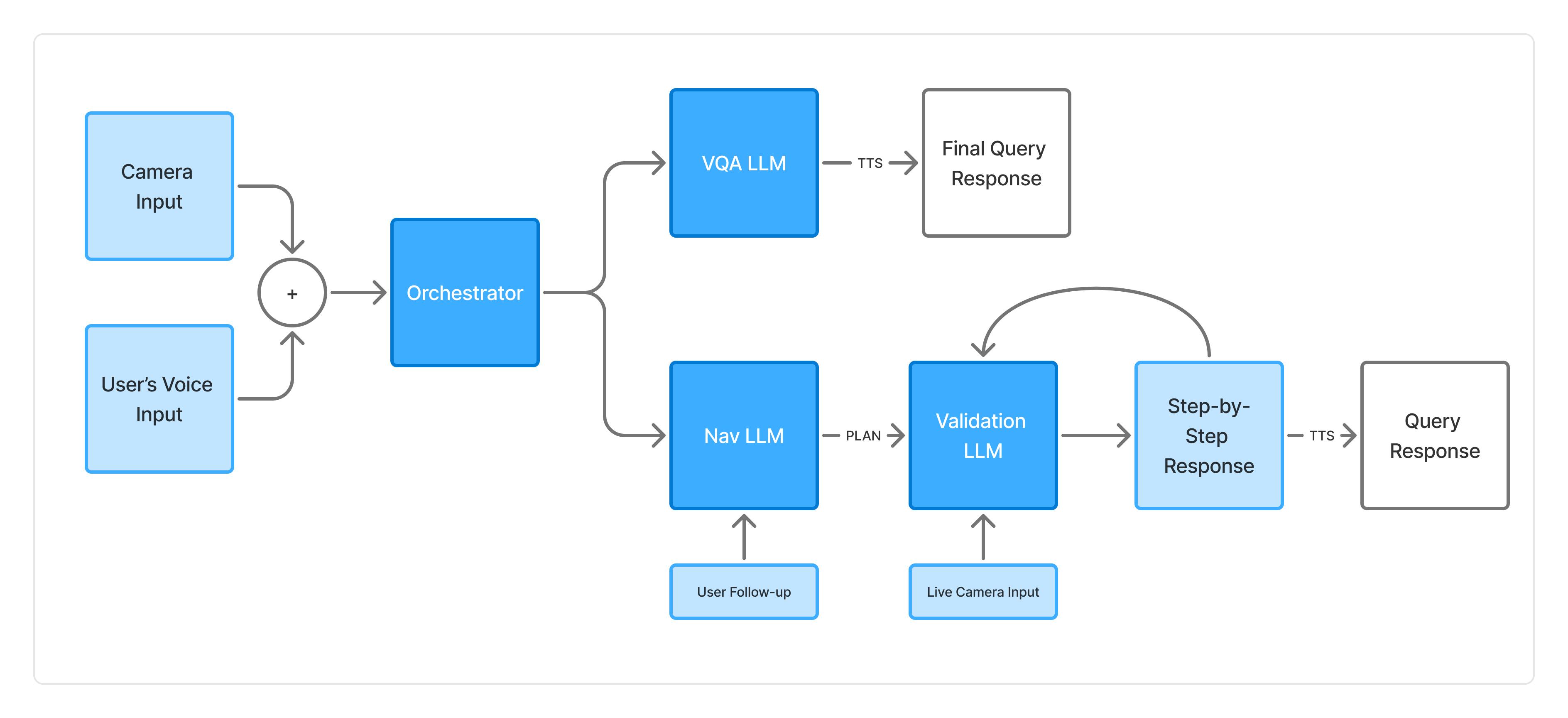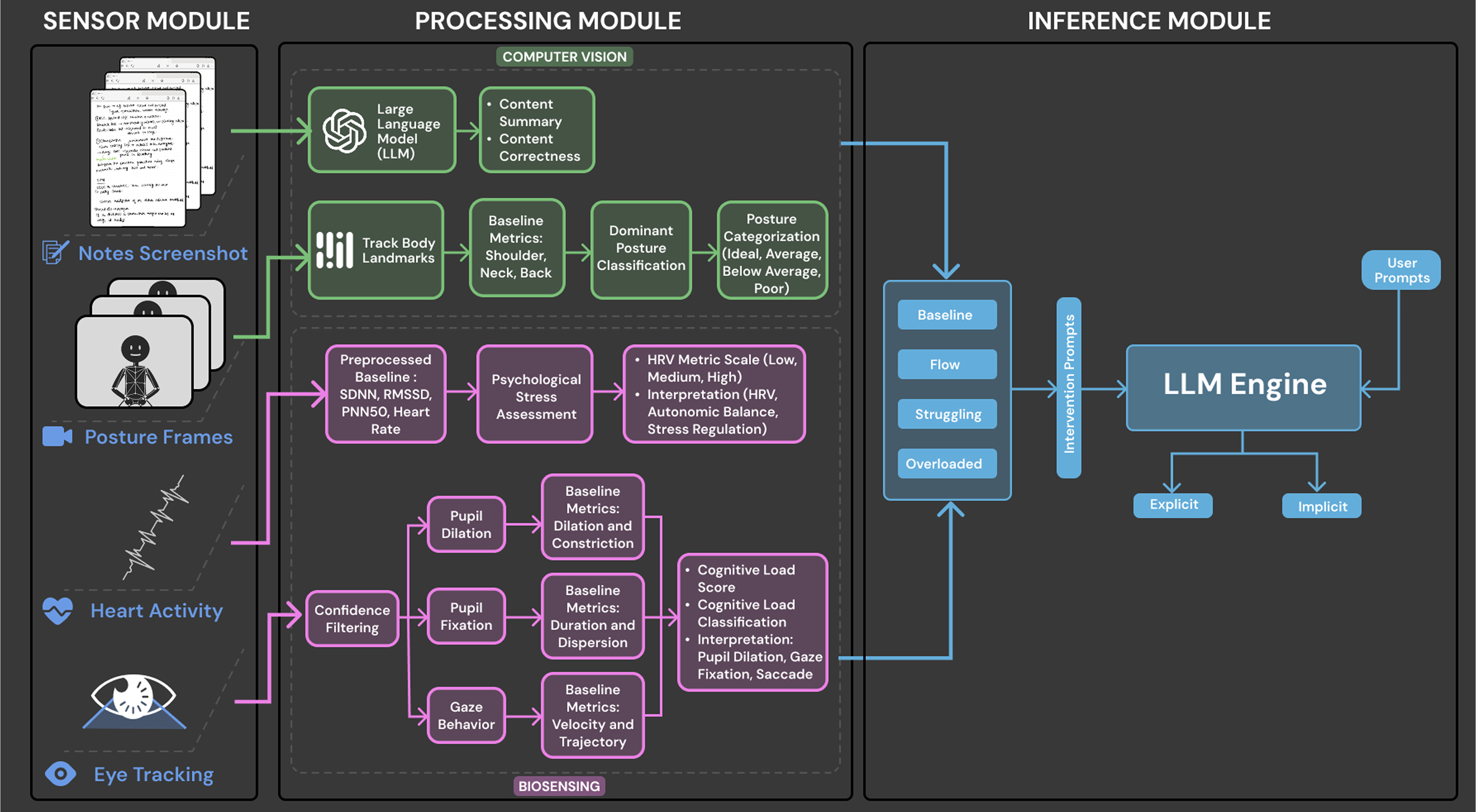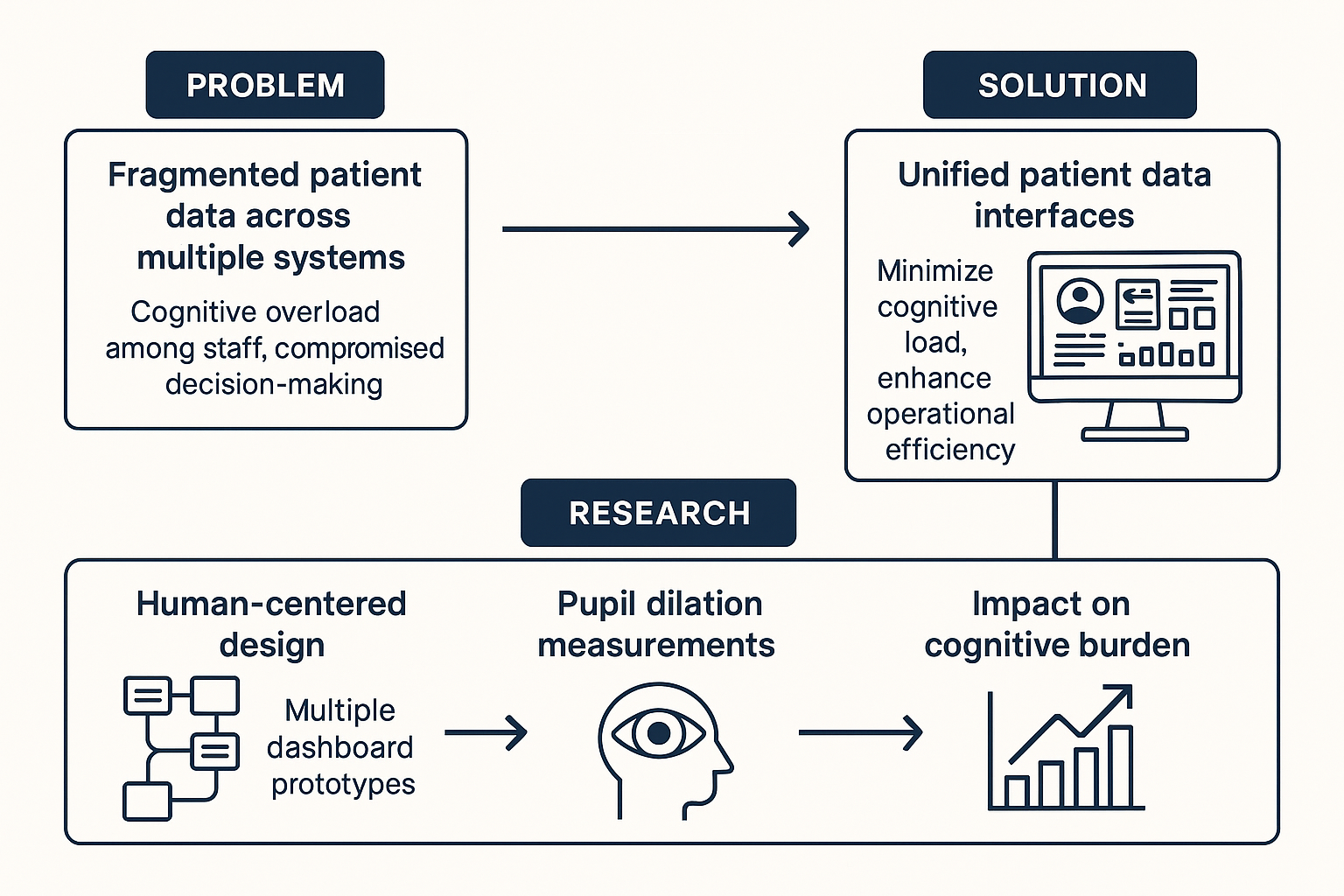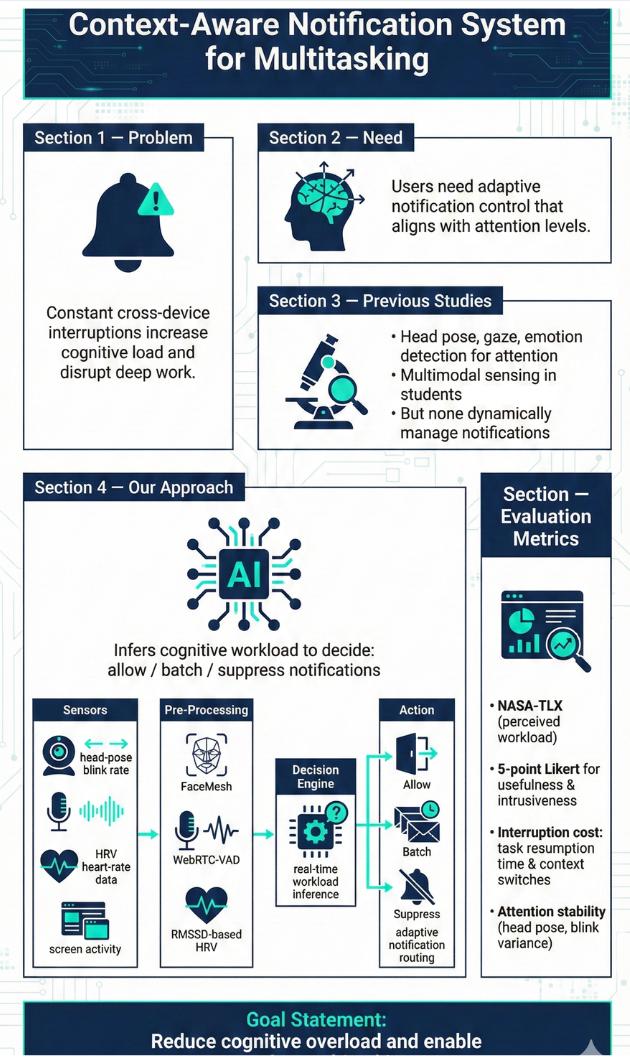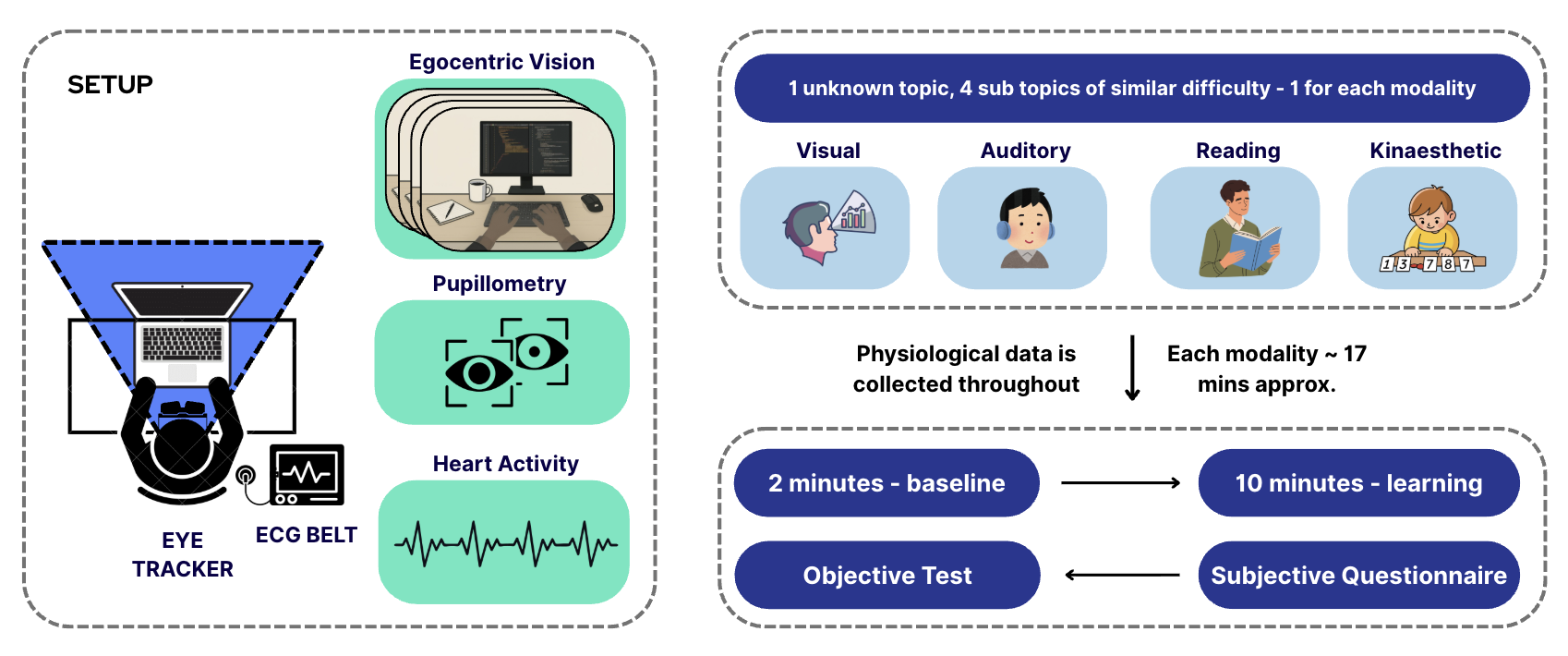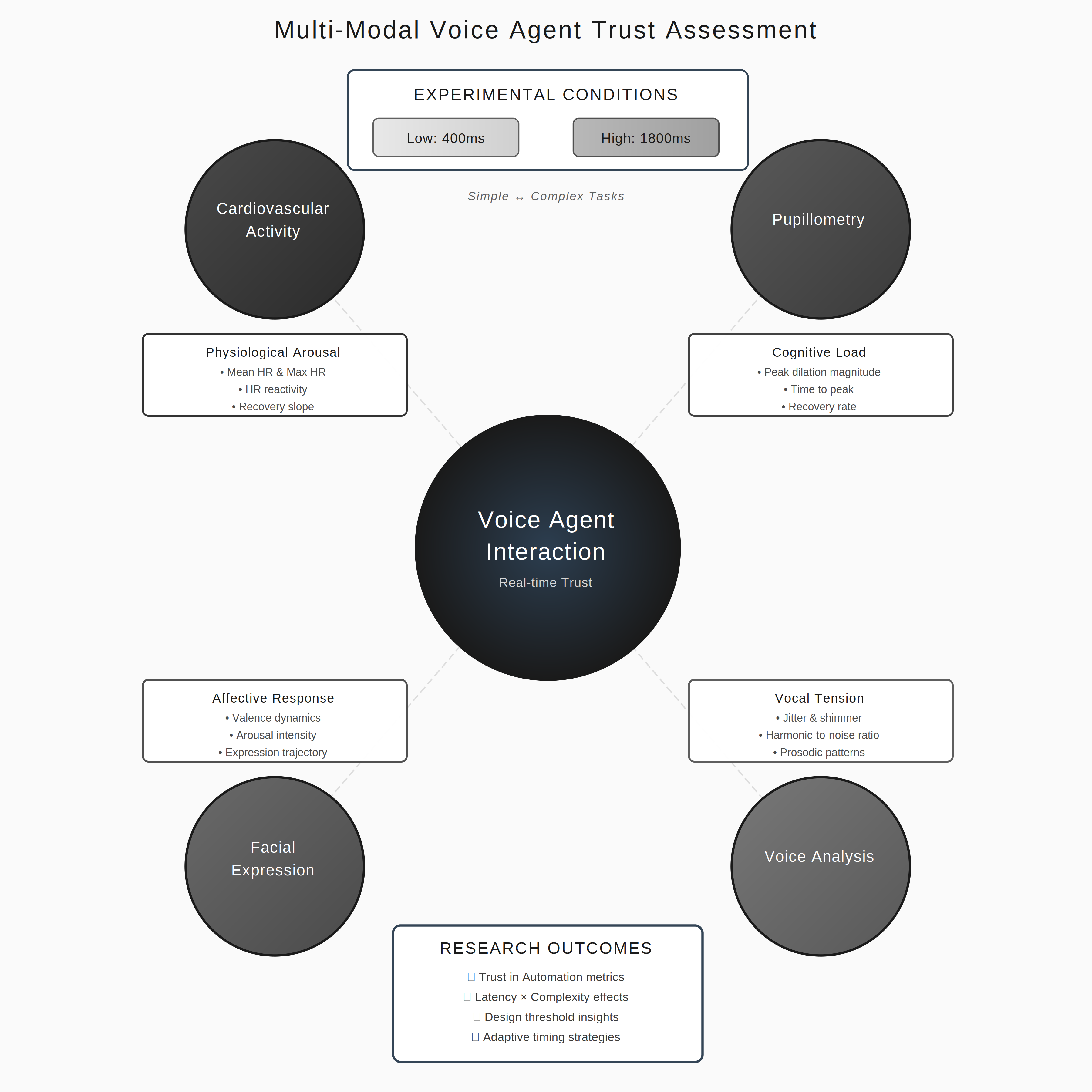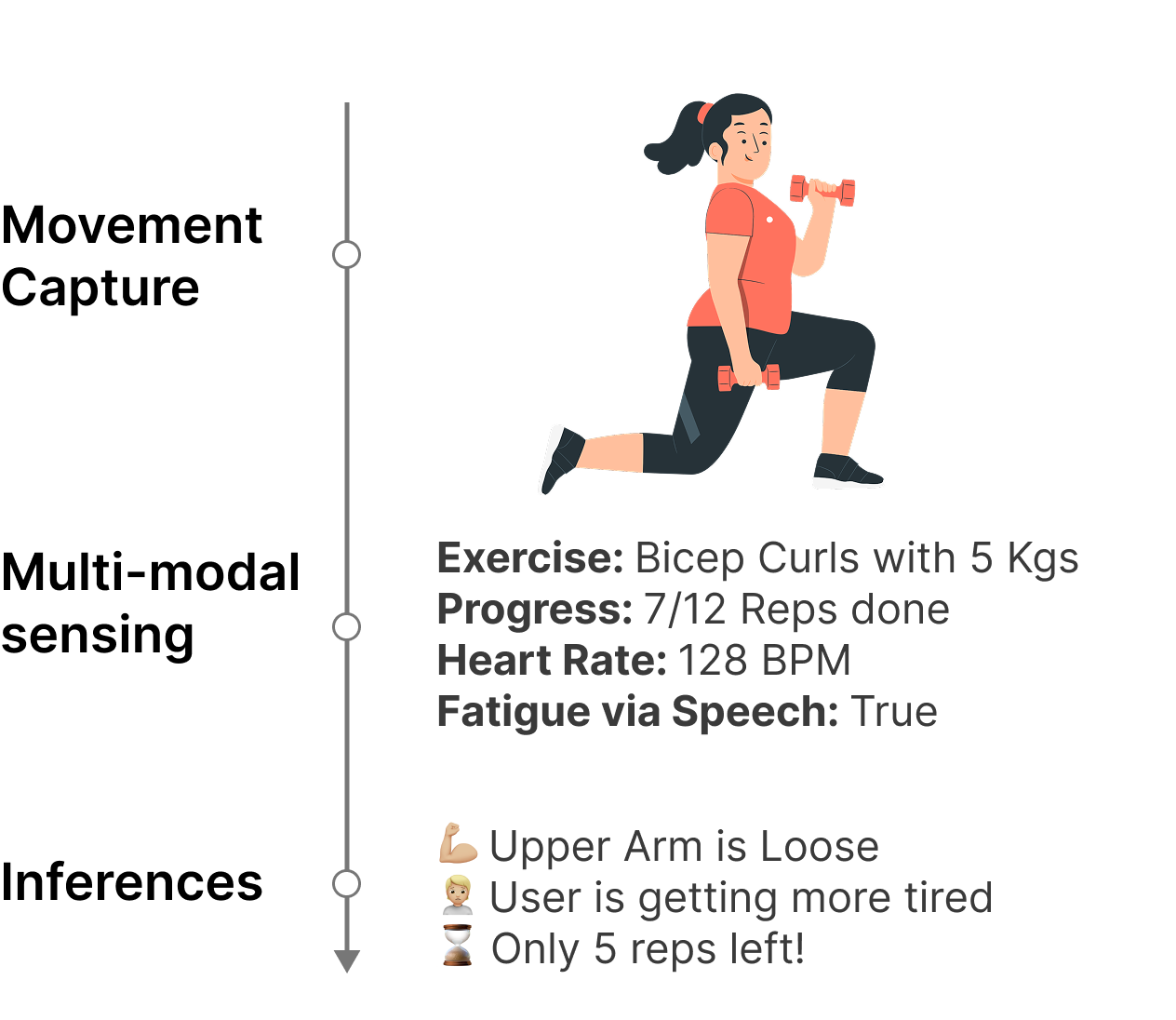
Maintaining fitness consistency is challenging due to the high cost of personal trainers and the static nature of existing applications, often resulting in unused memberships and injury risks. To address this gap, we present Dumbl, a market-ready solution built upon our research system FlexAI. This real-time, multi-modal adaptive framework integrates computer vision, bio-sensing, and Large Language Models (LLMs) to provide instant, personalized interventions. Informed by a formative study of 90 participants, our methodology employs MediaPipe for pose estimation, a fine-tuned ResNet-18 model for pain classification (achieving 79.3% accuracy), and audio analysis for fatigue detection. An integrated LLM synthesizes these physiological inputs to generate context-aware, tone-adaptive feedback. A comparative user study with 20 participants revealed that the system significantly reduced negative emotional states, with users reporting lower exhaustion (p=0.0103) and discouragement (p=0.036) compared to a control group. Additionally, participants experienced significantly less boredom (p=0.0258) and higher enjoyment, demonstrating the system's ability to effectively simulate expert human coaching through dynamic physiological adaptation.